The Self-Referential AI Tooling Loop
Every sufficiently advanced content pipeline eventually ingests itself. This is not a bug or a curiosity — it is a distinct architectural pattern with specific engineering requirements, failure modes, and compounding dynamics that differ fundamentally from pipelines that only process external data.
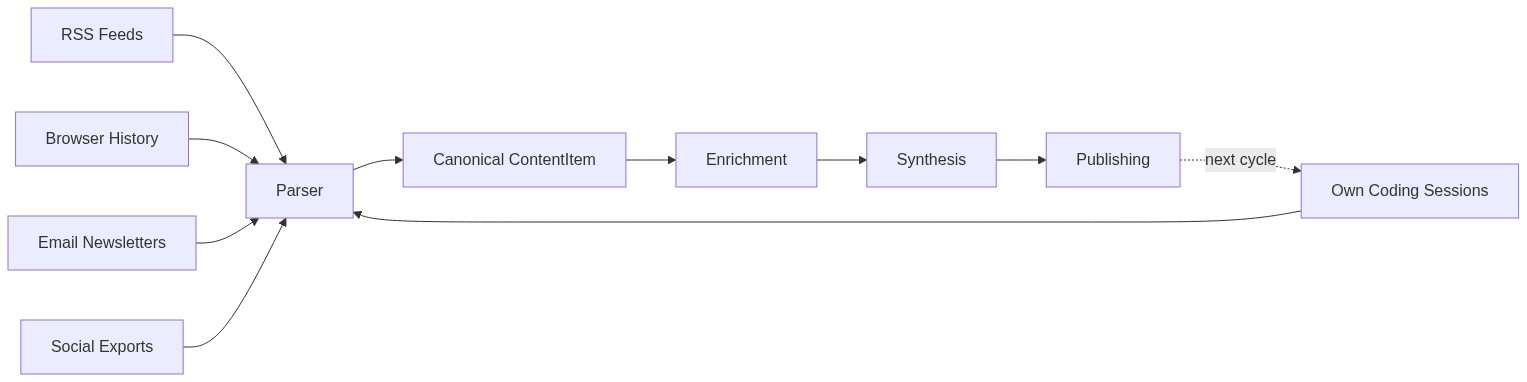
The pattern works like this: a tool that processes coding sessions generates its own coding sessions as a byproduct. Those sessions become input. The tool's output shapes the context that influences the tool's next run. What starts as a linear pipeline — raw data in, formatted content out — bends into a loop where production and consumption share a substrate.
Getting this loop to work requires deliberate engineering at three specific points: the intermediate representation, the extraction format, and the review gate. Get any one of these wrong and the loop either breaks or, worse, silently degrades.
The Canonical Representation Problem
The critical design decision is not how to parse your own output. It is how to make your own output indistinguishable from external data at the point where processing begins.
A content pipeline that ingests RSS feeds, browser history, email newsletters, and social media exports needs a canonical intermediate representation — a single data structure that absorbs the heterogeneity of eight or nine different source formats. When you add your own coding sessions as a tenth source, the architecture faces a fork. You can special-case the self-referential input, routing it through a dedicated path with its own enrichment logic. Or you can write a thin adapter that maps session data onto the same canonical representation everything else uses, and let the downstream pipeline handle it identically.
The adapter approach wins, and it is not close. A session parser that emits the same canonical content objects as the RSS parser means the intelligence layer — entity extraction, classification, embedding — runs the same code path regardless of whether it is processing an article about distributed systems or a coding session where you refactored that same intelligence layer. The downstream pipeline neither knows nor cares about provenance.
This matters because self-referential content is not special content. It is content that happens to describe the system processing it. The moment you treat it as special — with dedicated handlers, separate enrichment logic, different storage — you have created a maintenance burden that scales with every pipeline change. Every modification to the enrichment step now needs to be made twice: once for external content, once for self-referential content. The canonical representation collapses that to one change.
Extraction vs. Summarization
The second engineering decision determines whether the loop compounds value or compounds noise.
After each synthesis pass — a journal entry, a blog post, a digest — you need to carry context forward into the next cycle. The naive approach is summarization: ask the LLM to summarize what happened, store the summary, inject it into the next prompt. This produces dead-end context. "We discussed storage options and selected a vector database" is technically accurate and functionally useless. It gives the next cycle nothing to build on, agree with, or revise.
Structured extraction with typed fields changes the dynamics entirely. Instead of a summary, you extract decisions with rationale and revisit conditions, open questions with enough context to evaluate them later, and themes with supporting evidence. "Decision: pgvector over FAISS for vector storage. Rationale: workload requires SQL joins against metadata columns. Revisit if: p95 latency exceeds 50ms." That is a forward hook. The next cycle can reference this decision, check whether the revisit condition has been met, or build on the rationale. An open question from Monday becomes a thread that Tuesday's entry picks up and advances.
The difference between these two approaches is the difference between a system that remembers and a system that learns. Summaries flatten temporal structure. Extractions preserve it.
Keeping the extraction as a separate subprocess call rather than inline processing is worth the added latency. When you are debugging why a journal entry confidently references a technical direction nobody actually chose, you need to inspect exactly what went into the extraction step and what came out. Separate processes give you that boundary. Inline processing buries it.
The Compounding Problem
Here is the property of self-referential loops that makes them genuinely dangerous: bad context compounds with exactly the same efficiency as good context.
Consider a slightly wrong decision attribution. The extraction step records that a storage choice was driven by performance requirements when it was actually driven by cost constraints. In isolation, this is a minor inaccuracy. But in a self-referential loop, this extraction feeds into the next cycle's context. The next synthesis pass treats it as established fact. By cycle three, the pipeline is confidently reasoning about performance optimization strategies that follow from a decision that was never actually about performance. The error is invisible to automated metrics. The pipeline runs cleanly. The output reads coherently. The attribution is wrong.
This is not a hypothetical failure mode. It is the natural tendency of any system where output feeds back into input without external correction. Douglas Hofstadter explored this dynamic in Godel, Escher, Bach — self-referential systems generate strange loops where levels that appear distinct collapse into each other. In a content pipeline, the "level" that generates content and the "level" that provides context for generation are architecturally separate but informationally entangled. Contamination at the context level is indistinguishable from ground truth at the generation level.
This makes human review a hard architectural dependency, not an optional quality improvement.
What Emerges After Several Cycles
Run the loop long enough and behaviors appear that nobody explicitly programmed.
After multiple extraction cycles fed context about recurring quality gaps back into agent prompts, development agents began proactively running type checkers and test suites before being asked. An observer role that was designed as a passive note-taker started synthesizing action items from disagreements between other agents. A development agent began running conflict pre-checks against the main branch while its QA counterpart was still writing a review — anticipating what would be needed next based on accumulated workflow context.
Whether this constitutes learning or is simply automated prompt engineering is an open question. The extracted context becomes part of the prompt, which reshapes behavior, which produces new sessions, which get extracted. The mechanism is clear. The distinction between "the agent learned" and "the agent received better context" may be artificial. The practical effect is the same: behavior changes across cycles without explicit reprogramming.
The generate-then-extract-then-inject loop is the minimal self-improvement cycle. It does not require reinforcement learning, fine-tuning, or any technique more exotic than three subprocess calls wired in sequence.
The Consumption Gap
The most insidious failure mode of a self-referential pipeline is not contamination. It is the growing distance between production rate and consumption rate.
Production scales with compute. You can run twenty synthesis passes in an hour, extract structured context from each one, and feed it all forward into the next cycle. Consumption scales with human attention. Reading and evaluating what the pipeline produces takes the same amount of time regardless of how fast the pipeline runs. Herbert Simon identified this asymmetry in 1971: "A wealth of information creates a poverty of attention."
In a self-referential system, this asymmetry is structural, not behavioral. You cannot promise yourself a dedicated review day and expect the problem to solve itself. The incentive gradient always favors building over evaluating, because building produces visible progress and evaluation produces invisible corrections. The only reliable mitigation is architectural: a review gate that bounds cycle time to human review cadence rather than compute cadence. If the gate is not enforced by the system, it will not be enforced at all.
The pipeline can run for a week with perfect task-completion metrics, green test suites, and coherent output while the feedback loop remains effectively open. Everything looks correct. Nothing has been evaluated.
When to Build One
Not every pipeline benefits from self-reference. The pattern is valuable when three conditions hold simultaneously.
First, the tool produces artifacts that are structurally similar to its input. A content pipeline that ingests text and produces text satisfies this naturally. A compiler that ingests source code and produces binaries does not.
Second, the context from previous runs is genuinely useful for future runs. If each run is independent — processing a batch of data with no temporal relationship to previous batches — the loop adds complexity without value. The loop pays off when there are themes, decisions, and open questions that persist across cycles.
Third, you are willing to enforce the review gate. A self-referential loop without human evaluation is not a learning system. It is an amplifier with no feedback signal, equally capable of amplifying insight and amplifying noise. If you cannot commit to reviewing output faster than the loop produces it, you are better off with a linear pipeline that at least does not compound its own errors.
The self-referential AI tooling loop is a real architectural pattern with real benefits — emergent behavioral improvements, compounding context, narrative coherence across time. It is also a system that will confidently drift in any direction, correct or not, at a rate proportional to its own efficiency. The loop is the easy part. The discipline is hard.