Deep Dive: agent reflection
Reflection is the mechanism by which a system improves without being redesigned. In reinforcement learning, it is the update step. In cognitive science, it is metacognition. In multi-agent orchestration, it is the difference between a system that repeats mistakes and one that compounds competence. The concept is simple enough to state and deceptively difficult to implement well, because the same capability that lets agents learn from their work can consume the system in recursive self-examination.
What Reflection Actually Means in Practice
Agent reflection, as I have built it in TroopX, is not introspection in the philosophical sense. It is a concrete three-phase process. After a dev-QA workflow completes — say, implementing a ping endpoint or a URL slugifier — a separate analyst agent spins up. This analyst reads the workflow's blackboard entries (structured findings from QA, test results, revision notes), reads the signal trace (who signaled what, when), and extracts specific learnings. Those learnings get written into role-specific memory files. The next time a dev or QA agent starts a new workflow, its system prompt includes the accumulated learnings from every prior run.
The architecture:
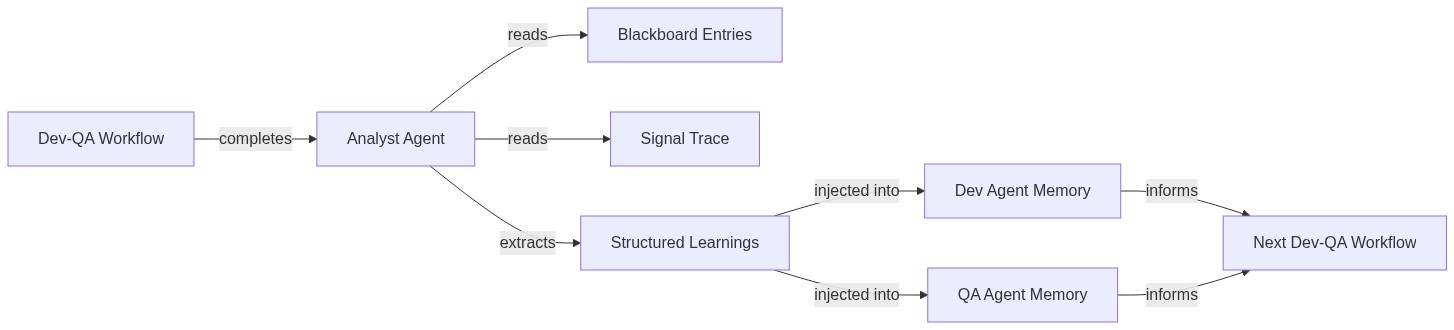
This is a closed loop. Execute, observe, extract, inject, execute again. Chris Argyris called the distinction between single-loop and double-loop learning: single-loop adjusts actions within existing rules, double-loop questions the rules themselves. Agent reflection as implemented here is firmly single-loop. The agents get better at following their roles, not at redefining them. That turns out to be the right constraint.
The Recursion Problem
The most dangerous property of reflection is that it is self-referential by construction. An analyst agent that examines workflow traces will, inevitably, examine traces that include previous analyst runs. Left unchecked, this produces a specific failure mode: the knowledge store fills with meta-observations about the observation process itself.
I watched this happen. The analyst would extract patterns like "analyst sessions average 4.2 minutes" or "QA agents poll for signals every 45 seconds." Both true. Both useless for any agent that is not an analyst. The knowledge store was accumulating accurate, well-structured noise.
The fix is a classification gate with three criteria. Every extracted learning must be: actionable by a non-analyst agent, grounded in a specific technical context (a file, a test result, a concrete error), and validated by at least one subsequent workflow where the pattern applied. This gate eliminates roughly half of what the analyst produces. That sounds aggressive. It is exactly right.
The distinction matters because it maps to Argyris's framework in a precise way. Meta-observations about the reflection process itself are double-loop candidates. They belong in system design discussions, not in agent memory injection. The classification gate enforces this boundary mechanically, preventing the system from attempting to redesign itself through its own feedback channel.
What Reflection Actually Catches
The value of reflection shows up in the revision cycle data. In the February 14 batch of four dev-QA workflows (truncate, repeat, slugify, join), two required revision cycles. QA caught that the repeat function's separator parameter was keyword-only when the spec expected positional usage. QA caught that truncate wasn't appending a default ellipsis suffix. Both are the kind of specification-adherence bug that a test suite alone would miss, because the tests were written by the same dev agent that wrote the implementation.
After the analyst extracted these patterns and injected them into subsequent dev agent memory, a specific behavioral change appeared: dev agents started cross-referencing their function signatures against the task specification before signaling completion. This is not a dramatic improvement. It is a modest reduction in first-pass revision rates. But it compounds.
By February 20, the post-workflow analyst loop was running in production across every completed workflow. Five analyst sessions and five reflection sessions in a single day, with dev and QA agents updating their working memory files with patterns they discovered during their own runs. The analyst extracts from the workflow; the agents reflect on their own performance. Two distinct feedback channels feeding the same memory layer.
The Ceremony Cost of Self-Knowledge
Reflection is not free. On February 18, four of ten sessions were post-workflow analysis and reflection passes. That is 40% of compute dedicated to learning rather than producing. The ratio demands justification.
The justification is asymmetric payoff. A single extracted learning that prevents a revision cycle in three subsequent workflows saves more time than the analysis consumed. A QA agent that knows the codebase's testing conventions from prior runs catches configuration issues faster. A dev agent with accumulated memory about endpoint patterns in this specific repository writes cleaner first-pass implementations. The investment pays off on volume, not on any individual workflow.
But there is a ceiling. Early in a system's life, extracted learnings eliminate common failure modes — unregistered workflow classes, forgotten default values, positional-versus-keyword parameter mismatches. Each new learning has high marginal value. After several dozen workflows, the common failures are already covered. The extraction keeps running, but the yield per session drops. The learning curve flattens.
This means reflection intensity should be adaptive. Dense extraction for the first twenty to thirty workflows when the learning rate is steep. Lighter extraction thereafter, perhaps running the analyst on every third completion rather than every one. I have not implemented this yet, but the data clearly argues for it.
Reflection vs. Retrospection
There is a useful distinction between reflection and retrospection that most agent systems collapse. Reflection happens automatically, within the system, feeding forward into future behavior. Retrospection is a human activity: reading traces, understanding what happened, deciding what to change architecturally.
The analyst agent does reflection. I do retrospection.
When I noticed the 45-second signal polling interval in QA agents (17 get_signals calls in a 13-minute session), that was a retrospective observation. No analyst would flag it because it does not cause workflow failures. It is a resource efficiency concern visible only to someone reasoning about the system's design, not its outputs. Similarly, the decision to use isolated git worktrees for concurrent workflows was a retrospective architectural choice, not something extractable from any individual workflow trace.
The boundary between these two activities is where most agent reflection systems go wrong. They try to make reflection do the work of retrospection — extracting architectural insights, proposing system redesigns, questioning coordination patterns. That is asking single-loop learning to do double-loop work. It cannot, and the attempt fills the knowledge store with abstract observations that no executing agent can act on.
The Memory Injection Interface
How learnings reach agents matters as much as what those learnings contain. In TroopX, agent memory lives in markdown files under the roster directory (~/.troopx/roster/dev/memory/MEMORY.md, ~/.troopx/roster/qa/knowledge/learnings.md). When a workflow spins up agents, the setup activity prepends this memory content into the agent's system prompt.
This is deliberately simple. No vector database lookup, no semantic retrieval at startup, no relevance scoring. The entire accumulated knowledge for a role loads as plain text. It works because the classification gate keeps the volume manageable. If every extracted pattern survived, the memory files would grow past useful context window sizes within weeks. The aggressive filtering upstream is what makes the simple injection downstream viable.
The alternative — semantic retrieval at agent startup — adds latency and complexity for marginal relevance improvement. When your knowledge store contains only validated, actionable, role-appropriate patterns, brute-force injection into the prompt is adequate. The sophistication belongs in extraction, not retrieval.
When Reflection Compounds
The inflection point for agent reflection arrived on February 20, when the system shifted from something I was building to something that builds with accumulated context. Twenty sessions, five analyst passes, five reflection updates, and the agents demonstrating measurably different behavior than they exhibited a week earlier.
The compounding effect is not linear improvement. It is threshold behavior. Below a critical mass of accumulated learnings (roughly ten to fifteen validated patterns per role), the memory injection has negligible effect. Agents behave the same with or without it. Above that threshold, specific behavioral changes become visible: dev agents cross-referencing specs before signaling, QA agents checking type annotations in addition to test results, both roles exhibiting tighter adherence to the codebase's conventions.
Donald Schön's The Reflective Practitioner describes how professionals develop expertise through reflection-in-action: adjusting behavior during performance based on accumulated tacit knowledge. Agent reflection mechanizes a crude version of this. The tacit knowledge is explicit (structured markdown), the adjustment is prompt-level (not architectural), and the reflection happens between performances rather than during them. But the dynamic is recognizable. Accumulated experience, structured and filtered, changes how the next engagement proceeds.
The system does not understand what it has learned. It carries forward text that, when included in a prompt, biases the next agent toward patterns that previously led to successful outcomes. That is enough. Reflection does not require comprehension. It requires a closed loop with a filter.