Deep Dive: agent-router
The most consequential design decision in a multi-agent system has nothing to do with agents. It's the communication substrate — the thing that sits between them, routing messages, tracking liveness, and enforcing state transitions. Get this layer wrong and agents fail in ways that look like intelligence problems but are actually plumbing problems. Get it right and the agents themselves become almost interchangeable.
The agent-router is a MCP server that provides six primitives: register, heartbeat, send message, signal workflow, read blackboard, write blackboard. That's the complete API surface. Every multi-agent workflow I've run over the past three weeks — content generation, code review, executive strategy sessions, medical consultations — reduces to combinations of those six operations. The constraint is intentional. Fred Brooks observed in The Mythical Man-Month that communication overhead grows quadratically with team size. The agent-router sidesteps this by making communication structured and mediated rather than peer-to-peer. Agents don't talk to each other directly. They talk through the router, which means the router can enforce protocols that agents alone cannot.
Two Layers, Deliberately Separated
The architecture splits into a signal layer and a data layer, and the separation is load-bearing.
Signals are an enumerated vocabulary: done, approved, needs_revision, blocked, progress, complete. Nothing else. When a dev agent finishes implementation, it doesn't send a paragraph explaining what it did. It calls signal_workflow with done. The QA agent polls get_signals, sees the transition, and begins its review. When QA finds problems, it signals needs_revision. The dev agent sees that signal and checks the blackboard for specifics.
The blackboard is the data layer. It's a namespaced key-value store where agents write structured findings — review entries with file paths and line numbers, analysis summaries, priority assessments. Any agent in the workflow can read any blackboard entry, which means shared state is explicit and inspectable rather than trapped in message histories.
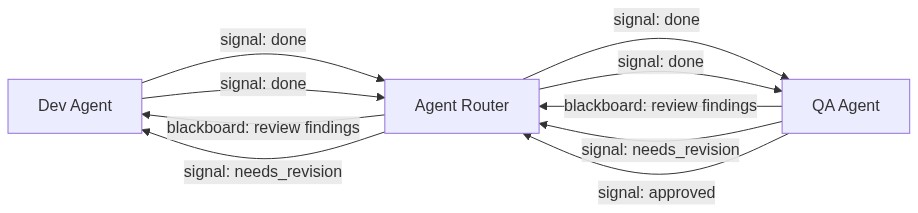
Why not combine them? Because signals answer "what state are we in?" while the blackboard answers "what do we know?" Conflating the two means either parsing free-text messages for state transitions (fragile) or cramming structured data into signal payloads (limited). A QA agent posting needs_revision to the signal layer and simultaneously writing detailed findings to the blackboard at review/findings is cleaner than either approach alone. I watched this play out concretely when a QA agent sent back revision notes on a repeat function — the signal told the dev agent something was wrong, the blackboard entry told it what was wrong (a positional vs. keyword-only parameter mismatch). The dev agent fixed the signature and resubmitted without any ambiguity about what was expected.
Heartbeats Are Not Just Liveness Checks
Every registered agent sends periodic heartbeats. The obvious purpose is liveness detection: if an agent stops heartbeating, the router knows it's gone. The non-obvious purpose is what the heartbeat returns — a count of pending messages. This turns a liveness signal into a synchronization primitive. An agent sitting idle, waiting for its counterpart to finish, doesn't need to poll its inbox separately. Each heartbeat already tells it whether anything has arrived.
On February 21, a CEO agent waiting for a content-writer to finish a blog post sent 94 heartbeats over the course of the session. Ninety-four pings with zero messages received for most of them. That looks wasteful in the logs. But each heartbeat cost microseconds, and the pattern it established — genuine idle-waiting rather than busy-looping or racing ahead — meant the CEO agent didn't start processing incomplete results or duplicate work. The heartbeat loop is a patience mechanism that happens to also be a liveness mechanism.
The dual-purpose design emerged from a problem I hit in early February. Agents were missing messages because they'd check their inbox once, find nothing, and proceed with assumptions. The heartbeat-with-pending-count pattern means an agent that's heartbeating cannot miss a message unless it actively ignores the count. The coordination failure mode shifted from "didn't know a message existed" to "chose not to read it," which is a dramatically easier problem to debug.
The Registration Protocol as Capability Declaration
Registration is the first thing every agent does, and it carries more weight than an existence announcement. Each register_agent call includes a workflow ID, a role, and implicitly declares what the agent will do in this workflow. The router uses this to scope message delivery and signal visibility.
This matters when workflows run concurrently. On February 18, I ran two dev-QA pairs simultaneously, each in its own git worktree. The agent-router kept their message spaces completely isolated because each pair registered with a different workflow ID. Dev agent A's done signal was invisible to QA agent B. Blackboard writes in workflow X didn't pollute workflow Y's namespace. The isolation came from the registration protocol, not from network segmentation or process boundaries.
The practical consequence: scaling from one concurrent workflow to four required zero changes to agent code. The router's per-workflow scoping handled it. The constraint that seemed bureaucratic during single-workflow testing became the mechanism that enabled parallelism.
What the Router Cannot See
Here is the fundamental limitation, and it took weeks to fully internalize. The agent-router has perfect visibility into its own domain — messages delivered, signals fired, heartbeats received, blackboard entries written. It has zero visibility into whether anything useful actually happened.
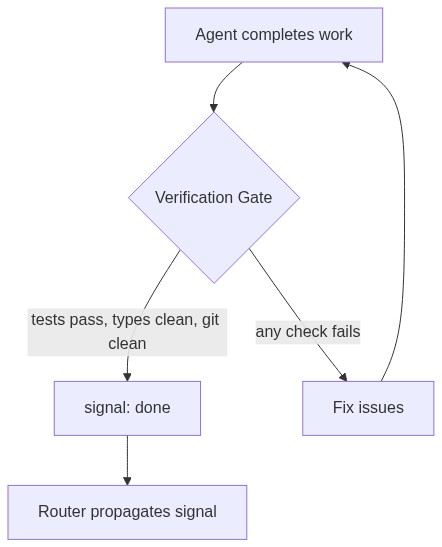
An agent can signal done without running the test suite. It can signal approved without reading the code. The router will happily propagate these signals because protocol compliance and outcome quality exist in completely separate observability domains. The signal layer tells you the workflow's shape — it progressed through the right states in the right order. It tells you nothing about the workflow's substance.
The fix is not in the router. It's in what happens before an agent is allowed to signal. A verification gate — a script that checks pytest exit codes, mypy output, and git working tree cleanliness — runs between "agent thinks it's done" and "agent signals done." The gate is application logic, not routing logic, and that boundary is important. The router stays simple because it doesn't try to understand work. It just moves messages and tracks state.
This separation is where Pat Helland's concept of "data on the outside" becomes relevant. Helland argues that data shared between services must be immutable and well-defined, while data inside a service can be messy and mutable. The agent-router enforces exactly this boundary. Inside an agent, anything goes — exploratory searches, failed edits, experimental branches. But the data that crosses the router (signals, blackboard entries) is structured and append-only. Agents can write to the blackboard but not delete from it. Signals are state transitions, not states — you can signal done but you can't un-signal it.
The Feedback Loop That Compounds
After each workflow completes, an analyst agent reads the blackboard entries and workflow signals, extracts patterns, and writes learnings back to the roster's knowledge directory. Those learnings get injected into agent prompts for subsequent workflows. By February 21, agents running content workflows already had accumulated context about formatting preferences, common revision triggers, and coordination timing. A content-writer that had received feedback about blog post structure in previous runs started producing cleaner first drafts because its prompt included those learnings.
The loop is: execute workflow → analyst reads artifacts → extract patterns → inject into future agents. The router enables this by making all workflow artifacts (signals, blackboard entries, message logs) available for post-hoc analysis. The analyst doesn't need special access — it registers like any other agent, reads the blackboard, and writes its findings. The same six primitives that run the workflow also support the meta-workflow of learning from it.
The risk is recursion. Analyst agents can extract patterns about the analysis process itself, filling the knowledge store with observations about observation. The containment mechanism is a classification gate applied at extraction time: every pattern must be actionable by a non-analyst agent, grounded in a specific technical artifact, and validated by a subsequent workflow where it changed behavior. Patterns that only analysts can use get filtered out.
Routing Is the Hard Problem
The agent-router is infrastructure. It moves bytes between processes. The genuinely difficult question it surfaces is not how agents coordinate but whether they should. A three-line configuration change doesn't need a dev-QA pair, a blackboard, and a revision cycle. A multi-module refactor does. The router serves both cases identically — same registration, same heartbeats, same signals — which means the router itself provides no guidance on when to use it.
This is by design. A switchboard doesn't decide who should call whom. But it means the highest-leverage component in the system isn't the router at all. It's the dispatch layer above it that examines a task, estimates its complexity, and decides whether to route it through full multi-agent orchestration, lightweight single-agent execution, or no coordination at all. The router makes that dispatch possible by providing a uniform protocol. The dispatch layer makes it worthwhile by ensuring the protocol gets used only when it earns its keep.
Six primitives. No intelligence. No opinions about what constitutes good work. The agent-router is deliberately less than what you'd expect from the center of a multi-agent system, and that restraint is precisely what makes it scale.